South 6th building: Room no. 209 (Server room), Room no. 210 (Experimental room), Room no. 217 (Yamashita), Room no. 218 (Students).
- Pattern recognition
- Image coding
- Computer Architecture
- Text Oriented Bi-Stream Explaining (TOBE) System
Pattern recognition and learning
Recently, the number of digits of postal number in Japan is changed from 5 to 7. Its reason is that the recognition rate for recognizing Chinese characters is low. Since 7 digit postal number includes the information for the part of address written with Chinese characters, computers don't have to read Chinese characters and improve the automation of postal services. This example shows that the recognition accuracy for pattern recognition is not enough. In order to improve the recognition accuracy, we conduct the following themas- Extension of kernel method and its applications
- normal distribution of manifold
- relative principal component analysis
Extension of kernel method and its applications
In kernel methods, patterns are mapped nonlinearly to very high or infinite dimensional space and are recognized by applying a linear classification method to the mapped patterns. By this method, linear methods can be extended to nonlinear methods. Let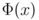 be such a nonlinear mapping.
However, it is difficult to use directly
since the result of the mapping
is a very high dimension vector.
However, only their inner product
be such a nonlinear mapping.
However, it is difficult to use directly
since the result of the mapping
is a very high dimension vector.
However, only their inner product
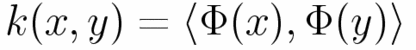
 ,
we can calculate many kinds of discriminating functions in the very high dimensional space indirectly.
The method by which we can transform
calculations in very high dimensional space to
those of a low dimensional space by the kernel function
is called 'kernel trick'.
,
we can calculate many kinds of discriminating functions in the very high dimensional space indirectly.
The method by which we can transform
calculations in very high dimensional space to
those of a low dimensional space by the kernel function
is called 'kernel trick'.
The traditional kernel method is given by the inner product of results of the same nonlinear mapping. In our laboratory, we extend it as the following formula.
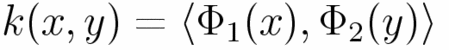
The following table shows the result of recognition experiment
with standard test set
by SVM with the ordinary kernel method and
by SVM with the extended kernel method.
| Method | Error rate (Data: Banana) | Error rate (Data: Diabetes) | Error rate (Data: Thyroid) | |
| SVM | 11.53 | 23.53 | 4.80 | |
| Extended SVM | 10.44 | 23.24 | 4.05 |
We can see advantages our methods.
Since the extended kernel method uses two nonlinear mappings, the number of parameters is increased and we have to research about this method.
Normal distribution on manifold
The normal distribution is widely used in statistical methods. For example, the distributions of measurement error and velocity of ideal gas are given by normal distributions. Furthermore, many distributions such as chi-square and F distributions are derived from normal distribution. By the way, what is a normal distribution? In many books, it is defined as the following probability density function.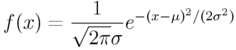
- Characterization by C.F.Gauss
Assume that a random variable distributes around the true value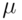 .
Its probability density function
.
Its probability density function
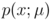 depends only on
depends only on 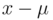 .
Assume that samples are given independently.
In this case we are happy if the maximum likelihood estimator is given by their mean.
The distribution which satisfies this feature should be a normal distribution.
.
Assume that samples are given independently.
In this case we are happy if the maximum likelihood estimator is given by their mean.
The distribution which satisfies this feature should be a normal distribution.
- Maxwell distribution of ideal gas
Assume that pairs of random variables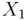 and
and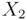 , and
, and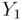 and
and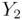 satisfies the following relation.
satisfies the following relation.
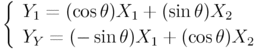 .
and are independent and
andare also independent,
the distribution of andshould be a isotropic normal distribution.
.
and are independent and
andare also independent,
the distribution of andshould be a isotropic normal distribution.
- Maxwell-Boltzmann distribution
Assume that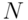 particles, which can be distinguished, are distributed into
particles, which can be distinguished, are distributed into 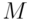 cells.
We also assume that in order to put a particle into the cell
cells.
We also assume that in order to put a particle into the cell 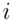 we need energy
we need energy 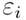 .
Even if the number of particle put into each box is fixed,
we can consider the number of cases since particles are distinguished.
The number is given as
.
Even if the number of particle put into each box is fixed,
we can consider the number of cases since particles are distinguished.
The number is given as
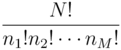
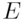 as well as the number of particle
and maximize the number of cases,
the number of particles in the box
is proportional to
as well as the number of particle
and maximize the number of cases,
the number of particles in the box
is proportional to 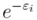 .
Since the kinetic energy are proportional to the square of velocity,
a normal distribution are derived.
.
Since the kinetic energy are proportional to the square of velocity,
a normal distribution are derived.
- Maximum entropy
A distribution that maximizes the entropy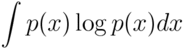
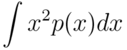
- Central limit theorem
For any distribution, we assume that its samples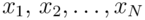 can be given independently.
Their mean divided the square root of variance
can be given independently.
Their mean divided the square root of variance
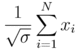
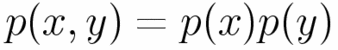 ,
,
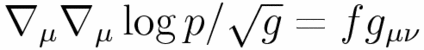 ,
,
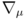 denotes
a covariant differential.
A distribution that satisfies this equation in a Euclid space
is a normal distribution in a ordinary sense.
We investigate pattern recognition and Maharanobis metric
by using this equation.
Until now, although advantages in a engineering sense are not obtained,
we consider it is a nice research theme since the equation is
beautiful.
(Don't you think so.)
denotes
a covariant differential.
A distribution that satisfies this equation in a Euclid space
is a normal distribution in a ordinary sense.
We investigate pattern recognition and Maharanobis metric
by using this equation.
Until now, although advantages in a engineering sense are not obtained,
we consider it is a nice research theme since the equation is
beautiful.
(Don't you think so.)
Relative principal component analysis (RPCA)
Principal component analysis (PCA) is used to extract principal components from a stochastic signal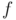 .
It can be achieved by the following criterion
for a matrix
.
It can be achieved by the following criterion
for a matrix 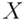 with the restriction of its rank.
with the restriction of its rank.
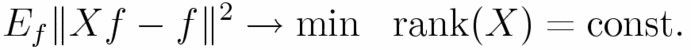 ,
,
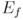 denote expectation with respect to .
Our laboratory are proposing
relative principal component analysis that is an extension of PCA.
RPCA can extract components
that which approximate the signal
while suppressing to extract components of another signal.
Its criterion is given as
denote expectation with respect to .
Our laboratory are proposing
relative principal component analysis that is an extension of PCA.
RPCA can extract components
that which approximate the signal
while suppressing to extract components of another signal.
Its criterion is given as
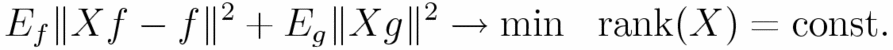
PCA is used for pattern recognition for
extracting features of a category.
By using RPCA we can extract
features that is included in a category
but is not included in other categories.
We made kernerized version of the criterion and
applied for various applications.
The following table shows the error rates
of the experiment with US postal handwritten number database.
| method | error rate [%] |
| PCA | 5.38 |
| RPCA | 4.91 |
| kernel PCA | 4.43 |
| kernel RPCA | 3.49 |
We can know RPCA and kernel PCA provide better performance than PCA and kernel PCA.
Image coding (Image compression)
Image coding, by which we can compress the data of an image, is very important technology for digital broadcasting and using an image in computers. However, as shown the following figures, the block distortion or ringing around edges is observed in a restoration image by JPEG that is the existing image coding standard. The left image is an original image.






In order to apply subband transform for moving image coding, we are investigating the motion compensation prediction with each pixel.
Computer architecture
The high speed processor is very important for image processing since the data size of image is very large. We need simple but very large amount of computations. The recent main theme for increasing performance is parallel processing such as chip multi processing. However, the ability of one processor is also essential even for parallel processing since the non-parallel part of computation limits the total performance. Then, our theme is increase of the performance of a processor.
Now we are investigating a new type of instruction cache memory system.
In that system, operation codes and operands are separately stored
into different cache memories.
Operands has the information of data dependency
so that its records are arranged in order.
The record of an operation code has a pointer to operand table
so that they are rearranged for increasing calculation speed.
The following figure illustrates the block diagram of PACCS-5.
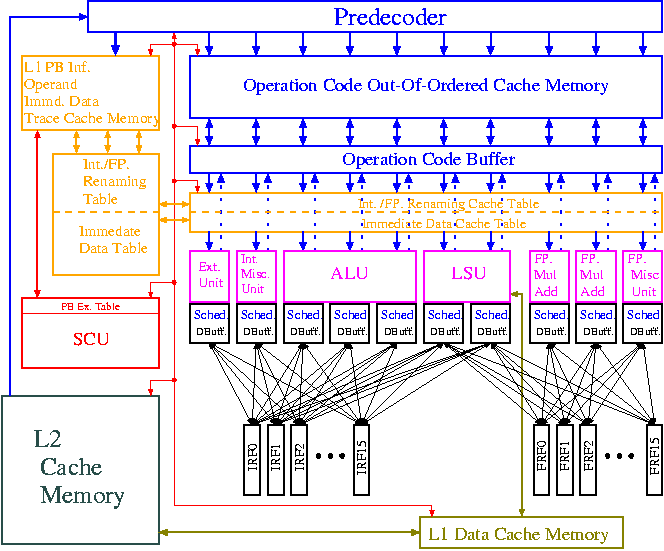
We can see that the cache memories for operation codes and operands are separated. The following figure illustrate the pipeline of PACCS-5.
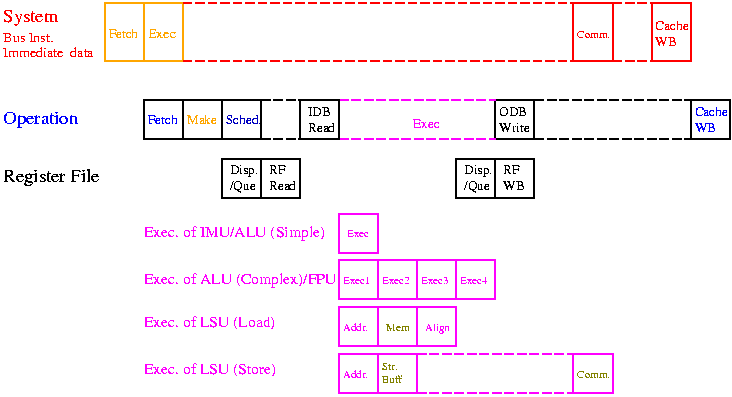
A new processor is developed by , many researchers (from several ten to several hundred) so that our developing speed may be less than one of a company. However, since various kinds of ideas can be introduced to our architecture, this theme is suitable for students who are interested in a micro-architecture of a processor since labs where they research a micro-architecture are not many.
TOBE System (Text Oriented Bi-stream Explaining System)
We are developing a system for international development called TOBE System. When we describe the content of board, speech, action by tobeML (Text Oriented Bi-stream Explanation Markup Language) text, a teacher drawn by CG gives an explanation with board, speech, and action. We are aiming a system which can do a simple lecture, an explanation of TIPS, and the manual of machine with explanation. And we are making a system like the Wiki. It enables us to write tobeML text by many writers. Then, since we can distribute our task to many teachers, the load for an individual teacher is decreased. Furthermore, we can accumulate very wide area of knowledge. We call such system 'TOBE system' and are developing it.We are dreaming as follows. When a man invented characters, we can accumulate knowledges. When a man invented printing, we can distribute knowledges to very many people. When a man invented Internet, everyone cat distribute their knowledge to people. However, in each case above, the knowledge are provided only by text or figures. Although, a man invented video system, it is difficult to create the content and its size of data is very large compared to text. The tobeML document is a text. Then, we can solve such problems. However, since the teacher created by CG explains with pointing the target on a blackboard, we can know easily what 'it' or 'that' in speech means. Therefore, TOBE System can improve the knowledge level of human beings and realize peaceful and wealthy world!!
- Bus Instruction Set Computer (BISC) architecture (in Japanese) (Nihon Kougyou Shinbun, daily, 1998, 3, 13, Friday, p16)
- VR system for robot (in Japanese) (Nihon Kougyou Shinbun, daily,1998, 3, 20, Friday, p27)
- Introduction of Yamashita Lab. (paper by students) (in Japanese)
- likes linear algebra,
- likes differential manifold,
- wants to design a high performance processor,
- wants to create a new method for pattern recognition or image coding,
- wants to make a system that contribute human beings by Java programming,
- worries about the future of human beings,
- is cheerful.
- We use Linux as the OS for personal computers (Fedora Core or Vine Linux). It is convenient to have learned Linux before come to our lab.

{kind=link}
{kind=link}